▤ 목차
The Purpose of Backpropagation
인공 신경망을 학습시키기 위한 알고리즘 중 하나
신경망을 학습시키는 목표 중 하나는 도출된 예측값과 실제 값의 차이(오차)를 줄이기 위함이다
그렇기에 역전파를 사용해 오차를 모든 가중치에 전달하여 갱신을 하며 궁극적으로 오차를 줄이는 기법이다
- 노드가 가지고 있는 가중치(weight)나 편향(bias) 같은 변수들을 어떻게 갱신(update) 하나?
- 노드의 변수들을 어떻게 개별적으로 얼마큼 업데이트 하나?
Chain rule(연쇄 법칙)을 이용해 위 두 가지 질문들을 해결할 수 있다
Chain Rule (연쇄법칙)
💡 Chain rule (연쇄법칙)
함수 $f, g$가 있을 때
$f$와 $g$가 모두 미분 가능하고
$F=f(g(x))=f \circ g$로 정의된 합성 함수이면 $F$는 미분 가능하다.
이때 $F'(x)=f'(g(x))⋅g'(x)$이다.
$t=g(x)$라고 한다면,
${dy \over dx} = {dt \over dx}{dy \over dt}$가 성립한다.
쉽게 말해 오차(label value - predicted value)부터 원하는 위치까지 한 번에 계산하기 위해 사용되는 기법이라고 생각하면 된다
미분이 가능하다 = 기울기를 구한다 = 변화량을 구한다
즉 x가 변화했을 때 함수 g의 변화량, 함수 f의 변화량, 그리고 최종 값 F의 기여하는 함수 f와 g의 기여도를 찾는 것
변수가 두 개라면 $z=f(x, y)$에서 $x=h(s, t), \,\,y=g(s, t)$일 때
$f(x, y),\, g(s, t),\, h(s, t)$가 모두 미분 가능하면 편미분을 사용한다
💡 편미분: 미분을 구할 하나의 변수만 변수로 두고 다른 변수는 상수로 취급하여 없애는 방법
$$ {\partial z \over \partial s} = {\partial z \over \partial x}{\partial x \over \partial s}+{\partial z \over \partial y}{\partial y \over \partial s} $$
$$ {\partial z \over \partial t} = {\partial z \over \partial x}{\partial x \over \partial t}+{\partial z \over \partial y}{\partial y \over \partial t} $$
Forward Propagation (순전파)
예측값을 도출하기 위해 변수와 가중치를 연산하는 것
데이터와 가중치를 연산하여 예측값을 도출하는 방법이라고 이해하면 된다
- 연결된 데이터 $x$와 가중치 $w$를 연산 후 더한 값이 $z$
- $z$를 활성화 함수 $a$로 연산
- $a$와 $w$를 연산 후 더한 값이 $z$
- $z$를 활성화 함수 $a$로 연산
- 최종층이면 연산 후 나온 값이 최종 예측값
- 그리고 실제값 $y$와 최종 예측값을 뺀 값이 오차다
- 아니라면 step 3과 4를 반복
- 최종층이면 연산 후 나온 값이 최종 예측값
Forward Propagation Example
$x, w, y$는 임의의 수를 정해 적어주었다
$z$와 $a$는 계산한 값을 표한다
직관적으로 표현하기 위해 activation function ($a$)는 sigmoid함수, cost function ($L$)은 mean squared error (MSE) 함수를 사용했다
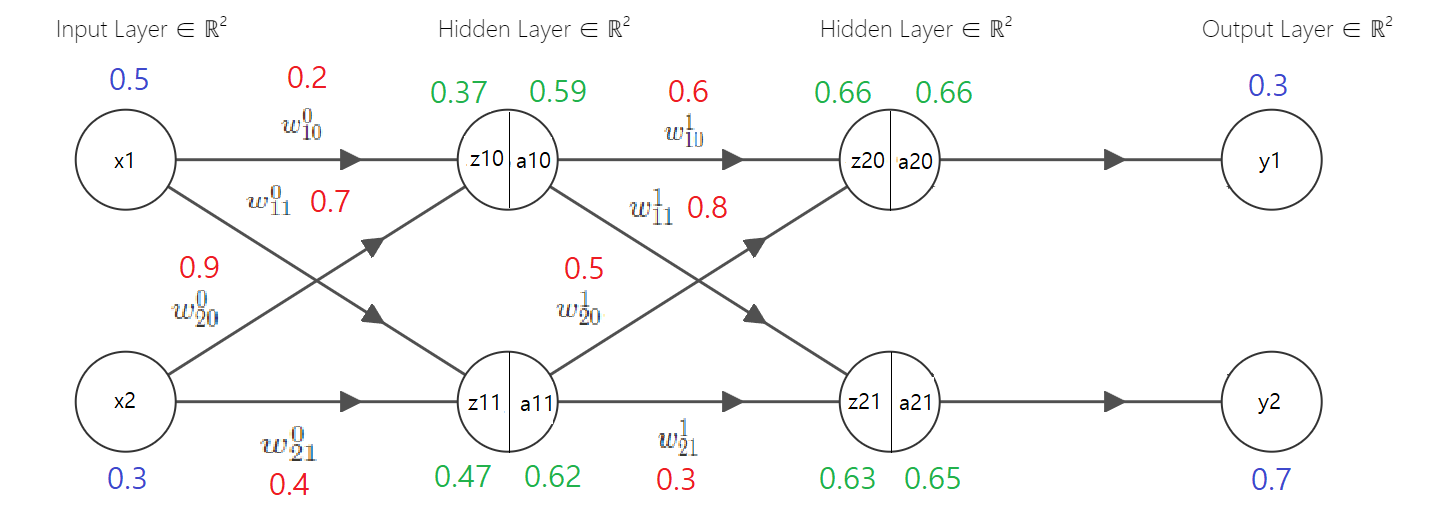
위 예시는 forward-propagation(순전파)을 한 예시를 보여준다
$$ z_{10}={x1 \brack x2} \times [w^0_{10} \, w^0_{20}] \\ z_{11} = {x1 \brack x2} \times [w^0_{11} \, w^0_{21}] $$
첫 번째 hidden layer의 연산 법은 아래와 같다
이를 풀어서 작성하면 아래와 같다
$$ z_{10} = x_1w^0_{10} + x_2w^0_{11} = (0.5 \times0.2)+(0.3\times0.9) = 0.1+0.27=0.37 \\ z_{11} = x_1w^0_{11} + x_2w^0_{21} = (0.5 \times0.7)+(0.3\times0.4) = 0.35+0.12=0.47 $$
구한 $z_{10}$과 $z_{11}$의 값들을 activation function인 sigmoid를 사용해 $a_{10}$과 $a_{11}$을 구해주며 sigmoid 수식은 다음과 같다
$$ \sigma = {1 \over 1+e^{-x}} $$
$$ a_{10} = sigmoid(z_{10})=0.59 \\ a_{11} = sigmoid(z_{11})=0.62 $$
이렇게 연산을 해서 구한 값들이 위 예제 그림에 보이는 값들이다
Backpropagation Example (Up to hidden layer)
순전파로 값들을 다 도출했으니 이제 역전파로 오차에 대한 변화량을 찾을 차례이다
먼저 cost function은 MSE를 사용하기로 결정했으며 수식은 아래와 같다
$$ MSE = {1\over n}\sum(y_i - \hat y_i)^2 $$
$y_i$는 정답, $\hat y_i$는 인공 신경망이 도출해 낸 예측값이다
MSE와 가중치 업데이트 수식을 이용해 가중치의 변화량을 찾을 수 있다
가중치 업데이트 수식은 다음과 같다
$$ w^+ = w - \eta * {\partial L \over \partial w} $$
$\eta$ 는 한 번에 얼마나 학습할지를 표현하고 ${\partial L\over \partial w}$는 어느 방향으로 학습할지를 표현한다
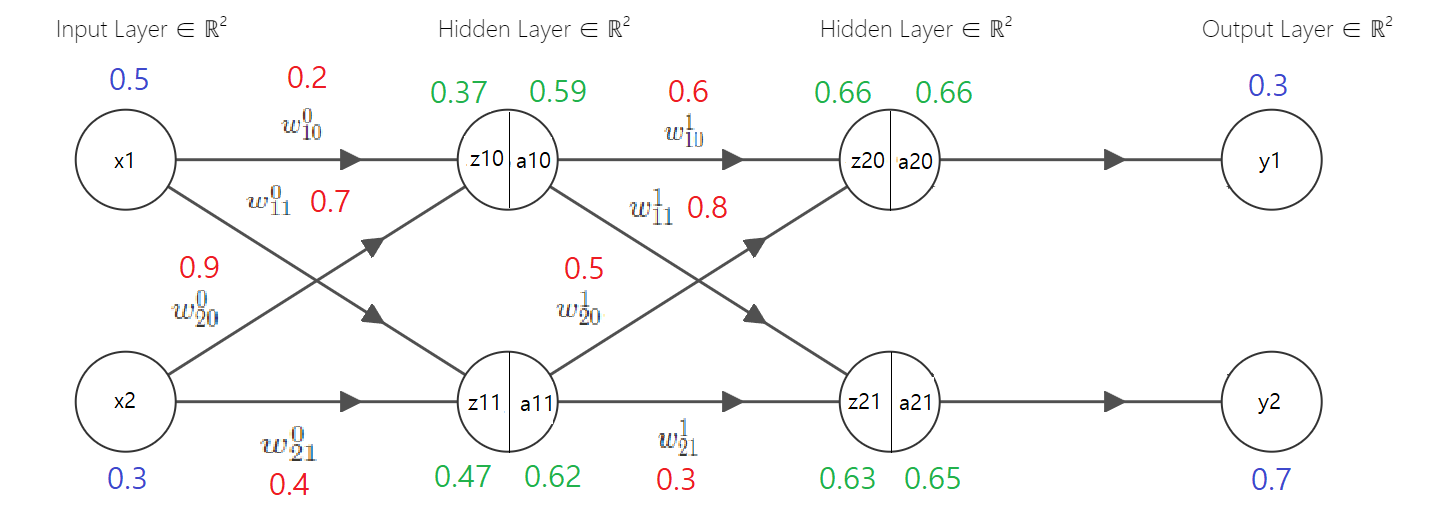
위 예제 그림 중 역전파를 이용해 $w^1_{10}$을 계산해 보자

Chain rule을 이용한다면 수식은 아래와 같다
$$ {\partial L\over \partial w^1_{10}} = {\partial L \over \partial a_{20}}{\partial a_{20} \over \partial z_{20}}{\partial z_{20} \over \partial w^1_{10}} $$
먼저 $\partial L \over \partial a_{20}$를 풀어보자. $L$의 수식은 다음과 같다
$$ L = {1\over 2}((y_1-\hat y_1)^2+(y_2-\hat y_2)^2) \\ L = {1\over 2}(y_1-\hat y_1)^2+{1\over 2}(y_2-\hat y_2)^2 $$
여기서 $\hat y_1$과 $\hat y_2$는 $a_{20}$과 $a_{21}$을 뜻하며 $w^1_{10}$만 업데이트해보려고 하기에 편미분을 통해 $a_{21}$은 상수 취급하여 무시하고 합성함수의 편미분을 이용해 풀면 된다
$$ {\partial L \over \partial a_{20}} = (y_1-a_{20})\times-1 = (0.3-0.66)\times -1 = 0.36 $$
계산결과인 0.36이 뜻하는 바는 $a_{20}$이 오차인 $L$에 0.36만큼 기여했다는 것을 의미한다
그럼 ${\partial a_{20} \over \partial z_{20}}$을 계산해 보자. 먼저 알아야 할 건 sigmoid의 미분이다
$$ {\partial a_{20} \over \partial z_{20}} = sigmoid(z_{20}) \times(1-sigmoid(z_{20})) $$
$$ {\partial a_{20} \over \partial z_{20}} = a_{20}\times(1-a_{20}) = 0.66 \times (1-0.66) = 0.66\times 0.34 = 0.22 $$
다음은 ${\partial z_{20} \over \partial w^1_{10}}$을 계산해보자. 위와 마찬가지로 편미분을 사용하기에 도출되는 값은 $a_{10}$이 된다
$$ z_{20} = a_{10}w^1_{10} + a_{11}w^1_{20} $$
$$ {\partial z_{20} \over \partial w^1_{10}} = a_{10} = 0.59 $$
그럼 처음에 구하려고 했던 ${\partial L\over \partial w^1_{10}}$의 값은 다음과 같다
$$ {\partial L\over \partial w^1_{10}} = 0.36\times 0.22 \times 0.59 = 0.05 $$
$w^1_{10}$이 기여한 값은 0.05가 되고 가중치 업데이트 수식을 이용해 가중치를 갱신할 수 있다
$$ w^{1+}{10} = w^1{10} - (\eta \times {\partial L \over \partial w^1_{10}}) = 0.6 - (0.1 \times 0.05) = 0.595 $$
학습률은 사람이 정해줄 수 있는 하이퍼파라미터이며 일반적으로 0.1 이하를 정하기에 임의로 0.1로 정했다
이렇게 해서 가중치 $w^1_{10}$은 0.6에서 0.595라는 값을 얻게 되었고 다른 가중치들도 위와 같은 과정을 거쳐 업데이트가 가능하다
Backpropagation Example (Up to first hidden layer)
그럼 1번째 은닉층 계산에 사용되는 가중치 $w^0_{10}$을 업데이트 해보자
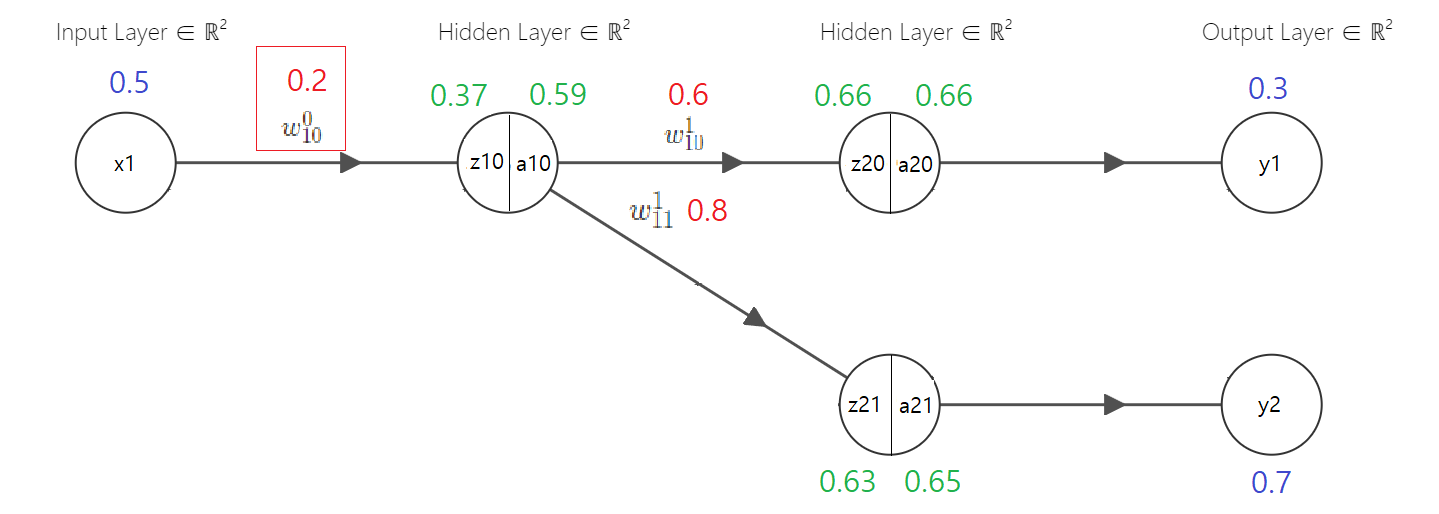
오차 $L$에 기여한 정도는 아래와 같이 나타낼 수 있다
$$ {\partial L \over \partial w^0_{10}} = ({\partial L_1 \over \partial a_{10}}+{\partial L_2 \over \partial a_{10}}){\partial a_{10} \over \partial z_{10}}{\partial z_{10} \over \partial w^0_{10}} $$
그럼 ${\partial L_1 \over \partial a_{10}}$부터 구해보자
$$ \begin {align} L_1 &= {1\over 2}(y_1 - \hat y_1)^2 \\ {\partial L_1 \over \partial a_{20}} &= (y_1-\hat y_1)\times -1 \\ {\partial a_{20} \over \partial z_{20}} &= a_{20}\times (1-a_{20})\\ {\partial z_{20} \over \partial a_{10}} &= w^1_{10} \end {align} $$
$$ \begin{align} {\partial L_1 \over \partial a_{10}} &= {\partial L_1 \over \partial a_{20}}{\partial a_{20} \over \partial z_{20}}{\partial z_{20} \over \partial a_{10}} \\ &= -(y_1-a_{20})\times \sigma(z_{20})\times(1-\sigma(z_{20})\times w^1_{10} \\ &= -(0.3-0.66)\times0.66\times(1-0.66)\times0.6 \\ &= 0.0484704 \end{align} $$
다음 ${\partial L_2 \over \partial a_{10}}$을 구해보자
$$ \begin{align} {\partial L_2 \over \partial a_{10}} &= {\partial L_2 \over \partial a_{21}}{\partial a_{21} \over \partial z_{21}}{\partial z_{21} \over \partial a_{10}} \\ &= -(y_2-a_{21})\times a_{21}\times(1-a_{21})\times w^1_{11} \\ &= -(0.7-0.65)\times0.65\times(1-0.65)\times0.8 \\ &= -0.0091 \end{align} $$
그럼 이제 ${\partial L \over \partial w^0_{10}}$을 구해보자
$$ \begin{align} {\partial L \over \partial w^0_{10}} &= ({\partial L_1 \over \partial a_{10}}+{\partial L_2 \over \partial a_{10}}){\partial a_{10} \over \partial z_{10}}{\partial z_{10} \over \partial w^0_{10}} \\ &= 0.05\times -0.01 \times 0.59 \times (1-0.59) \times 0.5 \\ &= -0.000060475 \end{align} $$
이를 토대로 가중치를 업데이트해보자
$$ w^{0+}{10} = w^0{10} - (\eta \times {\partial L \over \partial w^0_{10}}) = 0.2 - (0.1 \times -0.000060475) = 0.2000060475 $$
그럼 가중치가 미미하게 변화하는 것을 볼 수가 있다
모든 가중치에 backpropagation을 진행한 것을 1 epoch 진행했다고 하며 epoch이 진행될수록 가중치가 갱신되며 오차가 줄어든다
이렇게 우리가 딥러닝 모델을 학습시킬 때 오차가 줄어드는 것을 볼 수가 있는데 실제로 backpropagation의 계산과정을 학습시키는 동안 보지는 않지만 이러한 과정이 들어간다는 것을 알고 있으면 좋다
'AI > Notes' 카테고리의 다른 글
| RFM (Recency, Frequency, Monetary) (0) | 2025.01.24 |
|---|


