▤ 목차
Manufacturing Data Definition and Processing
Overview of Manufacturing Data Collection
The dataset analyzed in this study was collected from the melting and mixing process during powdered cream production. This data was obtained via PLCs and a Database Management System (DBMS) with a collection cycle set at 6-second intervals. The data collection period spans approximately two months, from March 4, 2020, to April 30, 2020.
Data Structure and Attributes
The dataset consists of seven columns and a total of 835,200 observations. Key attributes are as follows:
| Column Name | Description | Data Type |
| STD_DT | Date & time of data collection | Object |
| NUM | Index | Integer |
| MELT_TEMP | Melting temperature | Integer |
| MOTORSPEED | Stirring speed | Integer |
| MELT_WEIGHT | Tank material weight (content) | Integer |
| INSP | Moisture content (%) of product | Float |
| TAG | Defect status (OK / NG) | Object) |
Important Notes on Variables:
- Melting Temperature & Stirring Speed: These values lack decimal points in the raw data, with an original format of nnn representing nn.n. Adjustments were made during preprocessing to restore accuracy.
- Material Weight (MELT_WEIGHT): Observations with 0 indicate an empty tank, such as prior to raw material loading or after process completion.
- Stirring Speed (MOTORSPEED): 0 speed indicates the equipment is in a non-operational state, such as during raw material loading, process completion, equipment malfunction, or operator breaks.
- Defect Status (TAG): The values "OK" and "NG" represent acceptable and defective products, respectively.
- Imbalanced Data: The dataset contains a significant imbalance, with fewer defective (NG) samples. This was addressed through advanced data balancing techniques in subsequent analysis steps.
Data Statistics and Null Values:
- Summary statistics revealed no missing values in the dataset, confirming its completeness.
- The data is primarily composed of continuous variables (e.g., temperature, stirring speed, material weight), with "TAG" being a categorical variable used as the target label.
- Visual inspection and statistical analysis identified normal distributions in some variables, with others requiring preprocessing to handle outliers or imbalances.
Key Takeaway:
The dataset provides a clean and comprehensive snapshot of the melting process, enabling effective analysis and predictive modeling.
Data Preprocessing and Visualization
Preprocessing Steps
- Date and Time (STD_DT):
- Although date and time themselves do not directly affect product quality, they can serve as proxies for external factors such as shifts in operating conditions.
- The STD_DT column was converted to datetime format and then decomposed into sub-columns for month, day, hour, minute, and second to evaluate their relationships with the target variable. The original column was subsequently removed.
- Melting Temperature and Stirring Speed (MELT_TEMP, MOTORSPEED):
- Both variables were originally recorded in integer form, lacking decimal points. To restore accuracy, each value was divided by 10 to reflect the intended nn.n format.
 01
01
- Both variables were originally recorded in integer form, lacking decimal points. To restore accuracy, each value was divided by 10 to reflect the intended nn.n format.
- Material Weight (MELT_WEIGHT):
- Outlier Detection:
- Initial data exploration revealed that the majority of values for MELT_WEIGHT clustered around three-digit figures, with a mode of 688 and a max of 55,252.
- However, boxplots and scatterplots identified a subset of values deviating significantly, showing spikes that were 10 to 100 times larger than adjacent data points (e.g., 655, 654, followed by 6,656).
- The data displayed patterns suggesting equipment malfunctions, such as transient sensor errors that recorded inflated weights during certain operational cycles.012
Weight cycle and outliers
- Outlier Correction Methodology:
- Given the cyclic nature of the process, a logical assumption was made that outliers should align with the typical three-digit weight range observed in the majority of data.
- Corrections were performed using the following rules, ensuring that anomalous values were systematically reduced to align with expected patterns:
- Outlier Detection:

| Range (Weight) | Transformation Method |
| ≥ 10,000 and < 55,252 | Divide by 100 to reduce to three digits |
| ≥ 7,000 and ≤ 10,000 | Divide by 1,000 and get the remainder to reduce to three digits |
| ≥ 1,000 and < 7,000 | Divide by 10 to reduce to three digits |
| ≥ 689 and < 1,000 | Divide by 10 to reduce to three digits |
| ≤ 688 | Retained as-is, assumed normal |
-
- Validation of Corrections:
- After corrections, a second boxplot confirmed that the outliers were effectively removed, restoring the expected cyclic distribution of MELT_WEIGHT.
- Scatterplots across time further validated that adjusted values aligned smoothly with operational patterns, indicating the issue was resolved.
After correction
- Validation of Corrections:
- Moisture Content (INSP):
- Moisture content values ranged narrowly between 3.17% and 3.23%, forming discrete clusters. This variable was treated as categorical and processed using one-hot encoding to preserve interpretability.
- Moisture content values ranged narrowly between 3.17% and 3.23%, forming discrete clusters. This variable was treated as categorical and processed using one-hot encoding to preserve interpretability.
- Defect Labels (TAG):
- The binary "OK" and "NG" labels were converted into numerical format (OK = 1, NG = 0) using a label encoder for compatibility with machine learning algorithms.
Visualization and Insights
- Correlation Analysis:
- A heatmap of correlations between variables and defect labels (TAG) identified the following as the most influential factors:
Heatmap - Melting temperature (MELT_TEMP)
- Moisture content (INSP)
- Stirring speed (MOTORSPEED)
- Time-related variables, such as month and day, also showed weaker correlations but were retained due to their potential indirect influence.
- A heatmap of correlations between variables and defect labels (TAG) identified the following as the most influential factors:
- Feature Distributions:
- Histograms and scatterplots provided an overview of variable distributions and cyclical patterns. For example, MELT_TEMP and MOTORSPEED exhibited periodic fluctuations in alignment with operational cycles, further supporting their inclusion in the model.


 012
012Feature plots
- Histograms and scatterplots provided an overview of variable distributions and cyclical patterns. For example, MELT_TEMP and MOTORSPEED exhibited periodic fluctuations in alignment with operational cycles, further supporting their inclusion in the model.
- Class Imbalance Analysis:
- A pie chart of defect labels revealed a 4:1 ratio between OK (658,133 samples) and NG (177,067 samples), emphasizing the need for oversampling techniques during model training.

Label pie chart
- A pie chart of defect labels revealed a 4:1 ratio between OK (658,133 samples) and NG (177,067 samples), emphasizing the need for oversampling techniques during model training.
Key Takeaway:
Effective preprocessing removed inconsistencies, highlighted influential variables, and prepared the dataset for robust modeling. Visualization confirmed patterns and distributions essential for developing an accurate predictive system.
Data Splitting and Addressing Class Imbalance
Data Splitting
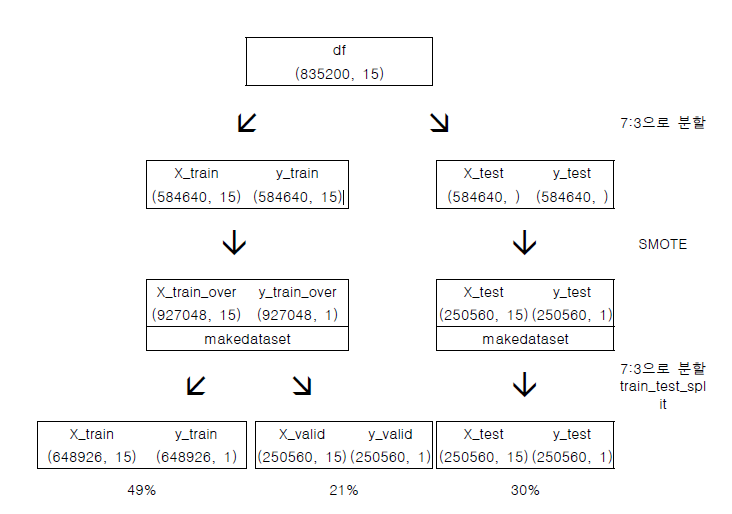
The dataset was split into three subsets: training, validation, and testing datasets, to ensure robust model training and evaluation.
- Initial Split:
- The dataset was divided into training (70%) and testing (30%) datasets.
- Care was taken to balance the distribution of defect labels (OK vs. NG) between these subsets, as the NG labels were concentrated within specific intervals. This was achieved by slicing the data from the middle rather than the end, ensuring a representative proportion of NG samples in the test set.
- Further Split for Validation:
Dataset Proportion Purpose Training Data 49% Model training Validation Data 21% Hyperparameter tuning and evaluation Testing Data 30% Final model evaluation - The training dataset was split into training and validation datasets in a 7:3 ratio. The final split was 49% training, 21% validation, and 30% testing datasets.
- The train_test_split function from Scikit-learn was used to implement this process.
Addressing Class Imbalance
The dataset exhibited a significant imbalance between the "OK" (majority) and "NG" (minority) classes, with approximately a 4:1 ratio. To mitigate this issue and ensure the model learned effectively from both classes, the Synthetic Minority Oversampling Technique (SMOTE) was applied:
- SMOTE Implementation:
- The SMOTE algorithm generates synthetic samples for the minority class (NG) by interpolating between existing samples and their nearest neighbors.
- This oversampling technique was applied to the training data, balancing the number of OK and NG samples to a 1:1 ratio.
- Results Post-SMOTE:
- The balanced training dataset consisted of an equal number of samples for both classes, allowing the model to learn patterns from both OK and NG samples without bias.
- The test and validation datasets were left unbalanced to reflect real-world distributions and provide an accurate evaluation of the model's performance.
Key Takeaway:
The data-splitting strategy ensured a fair distribution of labels across subsets. At the same time, the SMOTE algorithm effectively addressed the class imbalance in the training data, enabling the model to generalize better to unseen data.
Normalization and Windowing
Normalization
To ensure optimal model performance, normalization was applied to all continuous variables in the dataset. This step is particularly important for machine learning models, especially those involving neural networks, as it ensures consistent scaling and prevents any single feature from dominating the learning process.
- Why Min-Max Scaling?
- Min-Max Scaling transforms the range of continuous variables to a fixed range, typically [0, 1]. This ensures all features contribute equally to the analysis, eliminating bias introduced by varying scales (e.g., temperatures in the hundreds versus moisture percentages in single digits).
- Unlike standardization (which centers data around a mean of 0 and scales based on standard deviation), Min-Max Scaling preserves the original distribution of the data, making it particularly suitable when the data does not follow a normal distribution.
- Min-Max Scaling is computationally efficient, an important consideration given the large size of the dataset (835,200 observations).
- Implementation Details:
- The MinMaxScaler from Scikit-learn was applied, using the formula: x′=x−xminxmax−xmin where x is the original value, xmin, and xmax are the minimum and maximum values of the feature, and x′ is the scaled value.
- Benefits in This Context:
- Improved Model Convergence: Neural networks often perform better and converge faster when input values are scaled to small ranges.
- Alignment Across Features: By scaling all features to a consistent range, the model treats each variable equally, without some features disproportionately influencing the learning process due to larger magnitudes.
- Preserving Feature Importance: Unlike standardization, Min-Max Scaling ensures that meaningful patterns in variables like temperature or stirring speed—where relative differences are critical—are retained.
- Excluded Variables:
- The target variable (TAG) was excluded from normalization since it is a binary classification variable (0 for NG and 1 for OK), which does not require scaling.
Key Takeaway:
The dataset was normalized for consistent feature scaling by applying Min-Max Scaling, enhancing model accuracy and stability. This step allowed the RNN to focus on meaningful temporal relationships across variables without being influenced by magnitude discrepancies.
Sliding Window for Time-Series Modeling
Given the sequential nature of the dataset, a sliding window approach was employed to prepare the data for Recurrent Neural Network (RNN) training:
- Window Size:
- A window size of 10 was selected based on the cyclic patterns observed in temperature and stirring speed, where significant fluctuations occurred approximately every 10 intervals.
- Implementation:
- Features were segmented into overlapping 10-step sequences. Each sequence represented the data at time t-10 to t-1, with the label at time t serving as the prediction target.
- For example, a sample sequence included 10 timesteps (features) and one corresponding label, resulting in a 3D tensor for model input: (number of samples, 10, number of features).
- Output:
- Training data was transformed into X_train_over (features) and y_train_over (labels), with a shape of (927038, 10, 15) for the features and (927038, 1) for the labels.
- Similarly, testing data was transformed into corresponding 3D tensors for model evaluation.
Key Takeaway:
Normalization ensured consistent scaling of input variables, while the sliding window technique effectively captured temporal dependencies, enabling the model to predict quality outcomes based on sequential patterns.
'AI > Project' 카테고리의 다른 글
| 2nd K-AI Manufacturing Competition (3) (1) | 2025.01.15 |
|---|---|
| 2nd K-AI Manufacturing Competition (2) (1) | 2025.01.15 |
| 2nd K-AI Manufacturing Competition (0) (2) | 2025.01.15 |
| Marketing Strategy Proposal with Instacart Data Analysis (1) (0) | 2025.01.15 |
| Marketing Strategy Proposal with Instacart Data Analysis (0) (0) | 2024.12.23 |





