▤ 목차
Competition Overview

The AI competition, hosted by LG U+ and organized by Upstage, focused on leveraging artificial intelligence to enhance content recommendations within the child-centric media platform "아이들나라 (Children's Country)." This platform caters to young children and their families, offering a wide range of content, from engaging character-driven entertainment to educational materials. The competition invited participants to develop innovative recommendation algorithms capable of delivering personalized suggestions that align with the preferences of parents and children.
The key challenge was to propose an AI-powered recommendation model that could balance two primary goals:
- Children’s Engagement: Recommending content that captivates children and matches their viewing habits and preferences.
- Parental Intentions: Suggesting content parents deem valuable, educational, or appropriate for their child.
By utilizing real user data, including child profiles, parental interests, viewing history, and metadata, participants were encouraged to explore and test various recommendation system methodologies. This competition presented a rare opportunity to work with real-world datasets and refine AI models for practical, user-centric applications. Driven by a shared interest in advancing recommendation technologies, the team joined the competition, seeing it as a valuable chance to innovate and grow.
Evaluation Metrics
To rank participants' AI models, the competition employed two widely recognized metrics in recommendation systems: Recall@K and NDCG@K. These metrics assessed the accuracy and effectiveness of the recommendations in meeting user expectations.
- K: Refers to the number of top-ranked items considered in the evaluation. For this competition, K was fixed at 25, meaning only the top 25 recommended items were evaluated.
- Recall@K: This metric measures the proportion of relevant items successfully recommended within the top K results. It reflects how well the system retrieves items of interest to the user, regardless of their ranking. In this competition, Recall@K contributed 75% of the total score, emphasizing its importance in the evaluation process.
- NDCG@K (Normalized Discounted Cumulative Gain): Unlike Recall@K, NDCG@K incorporates relevance and ranking of recommended items. It rewards algorithms that position the most relevant items higher within the top K results. This metric made up 25% of the total score, complementing Recall@K by assessing ranking quality.
The formula for calculating the final competition score was:
Score = (Average Recall@K * 0.75) + (Average NDCG@K * 0.25) (with K set to 25).
These metrics ensured that the evaluation balanced the number of relevant recommendations (Recall) and their prioritization (NDCG), fostering the development of well-rounded and effective recommendation systems.
About the Service
Before analyzing the data, we recognized the importance of gaining a comprehensive understanding of the service itself to better contextualize and interpret the data. 아이들나라 (I-Nara) is a premium service dedicated to providing personalized educational and entertainment content for young children. The platform offers over 70,000 curated content pieces tailored to early childhood education and development, including storybooks, interactive learning modules, and engaging games. This ensures a holistic experience for both learning and recreation. Notably, 아이들나라 is accessible to all users, regardless of their telecom provider, with a free 7-day trial available to new subscribers (“아이들나라,” n.d.).
아이들나라 stands out for its integration of specialized services such as Disney Learning+, 화상클래스 (Live Online Classes), and 빨간펜 놀이수학 (Interactive Math Activities). These exclusive offerings are designed to foster cognitive and emotional development in children while engaging parents in the educational process. The platform’s affordability and variety make it a top choice for families seeking premium content for their children (“아이들나라 서비스,” n.d.).
The subscription plans are designed to cater to diverse needs and preferences, featuring four tiers: Premium, Standard, Play, and Learning. This flexibility allows families to select plans that align with their requirements, offering options such as unlimited access to learning-focused content or gameplay-oriented features. The service is accessible across multiple platforms, including mobile apps and web-based interfaces, ensuring convenience and ease of use for users (“아이들나라 요금제,” n.d.).
아이들나라 is committed to delivering innovative solutions that enhance the educational journey for young children. With its comprehensive library and user-friendly design, the service empowers parents to provide high-quality learning experiences that align with their children’s developmental needs.
References
“아이들나라.” n.d. Accessed November 10, 2022. https://www.i-nara.co.kr.
“아이들나라 서비스.” n.d. Accessed November 10, 2022. https://www.i-nara.co.kr/product.
“아이들나라 요금제.” n.d. Accessed November 10, 2022. https://www.i-nara.co.kr/faq.
Data
Due to the constraints of a Non-Disclosure Agreement (NDA), we are unable to disclose detailed information about the dataset. However, we can provide an overview of our approach to data handling and preprocessing.
The dataset consisted of seven CSV files, which included various data points such as viewing history, purchase records, and user profile information. The competition's ultimate goal was to train a recommendation model capable of predicting the content a user would watch next.
Since the data was split across multiple files, our first step was to analyze the relationships between the files using an Entity-Relationship Diagram (ERD). This allowed us to:
- Identify the primary keys in each file.
- Understand the connections between files.
- Map out the flow of data as it was loaded into sessions.
Where possible, we merged files that had similar attributes without compromising data integrity. For instance, the content file was combined with session data, viewing history, and purchase records since these files were complementary, and merging them did not alter the original data structure.
Exploratory Data Analysis (EDA) and Preprocessing
After consolidating the data, we conducted an Exploratory Data Analysis (EDA) to understand its characteristics and prepare it for modeling. Each file contained distinct attributes—such as gender, purchase history, and viewing duration—requiring a tailored preprocessing approach. Here are the key steps we took:
- Removal of Sparse Columns
- We excluded columns where more than 50% of values were missing to ensure data reliability.
- Elimination of Irrelevant Features
- We removed features with missing values that had little impact on recommendations.
- Missing Value Imputation
- For crucial features, we filled in missing values using appropriate statistical or domain-specific methods.
- Feature Simplification
- We simplified or removed overly detailed features.
- Example: We eliminated individual character attributes (Character 1–7) since non-primary characters weren't essential for recommendations.
- Time Data Standardization
- We converted string-formatted time fields into proper time formats.
- Example: We standardized entries like "0093 seconds" to "0133 seconds."
- Categorical Data Encoding
- We converted categorical variables to numerical formats for machine-learning compatibility.
- Example: We transformed binary values like "N/Y" to "0/1."
- Duplicate Removal
- We eliminated redundant entries to maintain data consistency.
This comprehensive approach ensured that the dataset was clean, structured, and ready for modeling, enabling us to build a reliable recommendation system.
Negative Sampling
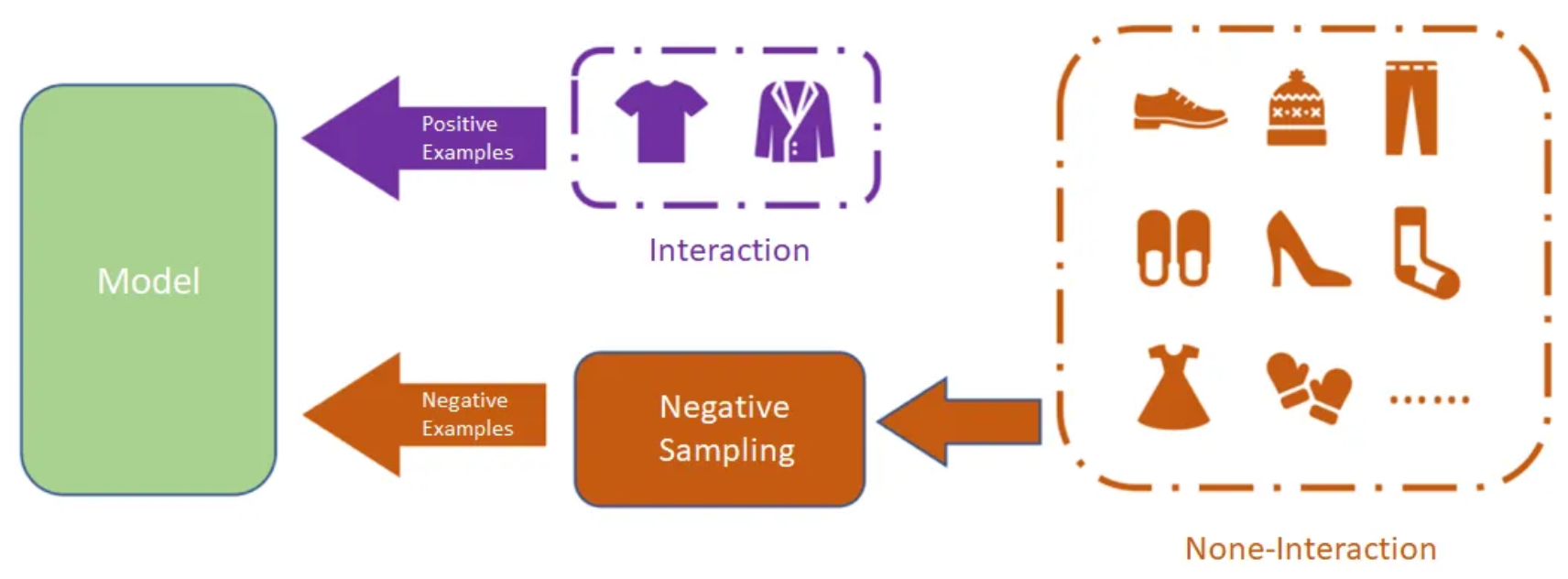
- Negative Sampling
- Random Negative Sampling (RNS)
- Popularity-biased Negative Sampling (PNS)
Negative Sampling is the process of identifying items that a user hasn't interacted with, which serve as "negative" examples in recommendation system training. While some systems use explicit feedback (like ratings), recommendation systems often rely on implicit feedback—treating items users haven't engaged with as negative samples.
In this competition, we represented items as content using binary classification. Content a user had watched was labeled as 1 (positive), while unwatched content was labeled as 0 (negative).
We explored two negative sampling techniques: Random Negative Sampling (RNS) and Popularity-biased Negative Sampling (PNS).
Random Negative Sampling (RNS)
RNS is a straightforward algorithm that randomly selects unwatched content as negative samples based on a preset ratio of positive to negative samples.
- Initial Experimentation:
- We first tested a ratio of 1:100 (positive:negative).
- This achieved a model performance score of 0.2143.
- Adjusting the Ratio:
- Following the NCF (Neural Collaborative Filtering) paper's suggestion, we tested ratios between 1:3 and 1:7.
- These adjustments yielded lower scores of 0.2003 and 0.1950.
Given these disappointing results, we turned to an alternative approach: Popularity-biased Negative Sampling (PNS).
Popularity-biased Negative Sampling (PNS)
PNS assigns sampling probabilities based on item popularity rankings. Unlike RNS's equal probability approach, PNS favors sampling frequently watched content.
- Mechanism:
- Popular content like "Pororo" received higher sampling probabilities.
- Niche content, such as European children's programs, received lower probabilities.
- Results and Challenges:
- PNS unexpectedly performed worse than RNS, with scores of 0.1901 and 0.1898.
- We found that PNS's focus on global popularity ignored individual user preferences, failing to capture personalized viewing patterns.
Our experiments revealed that neither RNS nor PNS with the proposed ratios significantly improved model performance. This underscores the importance of matching negative sampling methods to specific dataset characteristics and task requirements.
'AI > Project' 카테고리의 다른 글
| Vehicle Interior Detection (0) (0) | 2025.01.16 |
|---|---|
| 2022 LG Uplus AI Ground (1) (1) | 2025.01.15 |
| 2nd K-AI Manufacturing Competition (3) (2) | 2025.01.15 |
| 2nd K-AI Manufacturing Competition (2) (3) | 2025.01.15 |
| 2nd K-AI Manufacturing Competition (1) (2) | 2025.01.15 |






